
Video: Vector Embedding
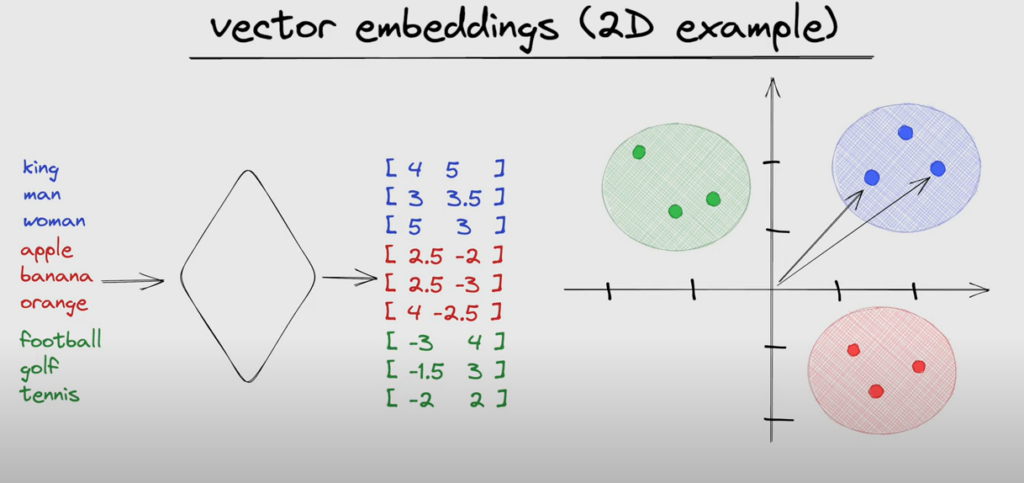
Vector embeddings are a technique used in natural language processing (NLP) to represent words or phrases in a continuous vector space. Here is a quick explanation:
– Each word is assigned a vector (array of numeric values) that represents the word in an abstract vector space.
– Words that are semantically similar end up close together in the vector space, allowing vectors to encode meaning based on context.
– Embeddings are generated using neural networks trained on large amounts of text data. The network learns to assign vectors to words that optimize the prediction task it is trying to solve.
– Word2vec and GloVe are two popular embedding techniques. Word2vec uses a shallow neural network to learn the vectors. GloVe uses matrix factorization methods.
– The resulting word vectors capture syntactic and semantic information. Vector arithmetic can be used to add and subtract meanings. For example, vector(“King”) – vector(“Man”) + vector(“Woman”) results in a vector close to the embedding for Queen.
– Embeddings allow words with similar meanings to have similar vector representations. This allows models to understand analogies and generalize patterns in language better.
– Vector dimensions are in the range of 50-1000. Higher dimensionality captures more information but is less computationally efficient.
– Embeddings are used as the first layer in many NLP deep learning models like LSTM, Transformers, etc. This provides a dense vector input representation instead of sparse one-hot encodings.